Scaling Real-Time Event Consolidation with GCP Dataflow
July 28, 2025
|
minute read
Blog


For a client in the freight services space, tracking parcels across time zones in real time was critical. Data was flowing in from various sources and needed to be stitched together into a single, meaningful stream to power tracking, billing, and reporting. Sounds straightforward but at scale, it’s anything but—unless you’ve got the right tooling.
Picture the massive conveyor systems at airports. Now add layers of complexity—barcode scanners, cameras, weighing scales, dimension-checking tools, manual movements. Each of these components generates something called a particle event.
When a parcel gets introduced on the machine it creates an event called an induct particle event. When the barcode scanner reads the barcode on the package it generates a barcode particle event; weight machines weigh the package and generate weight particle events; movement of a parcel from to another conveyor belt generates an output particle event.
Some of the particle events show up instantly; others may be delayed by minutes or hours. We need to stitch all the particle events of a single parcel together into a single Sort event to get the correct and complete information about each parcel in real time. For this article we will assume we don’t need to store this data permanently, we just need to create this Sort event and send a notification to another system.
This isn’t a new problem. Traditionally, old systems have stored each of these particle events in a database and used background workers to scan and consolidate the data. It works, until scale breaks it.
Heavy reliance on the database introduces scaling bottlenecks as load increases. You can’t scale your workers horizontally, and may end up needing synchronized processing or data partitioning to handle grouping logic safely to avoid race conditions. You’re also stuck running regular cleanup jobs to maintain database performance. It’s manageable, but far from elegant or efficient.
We moved the architecture to a streaming-first approach using GCP Pub/Sub to ingest event data and GCP Dataflow to consolidate it. GCP Dataflow is a Data streaming solution built on top of a framework called Apache Beam. Apache Beam is a parallel processing data framework.
Here’s the order of how the particle events might arrive for two parcels:
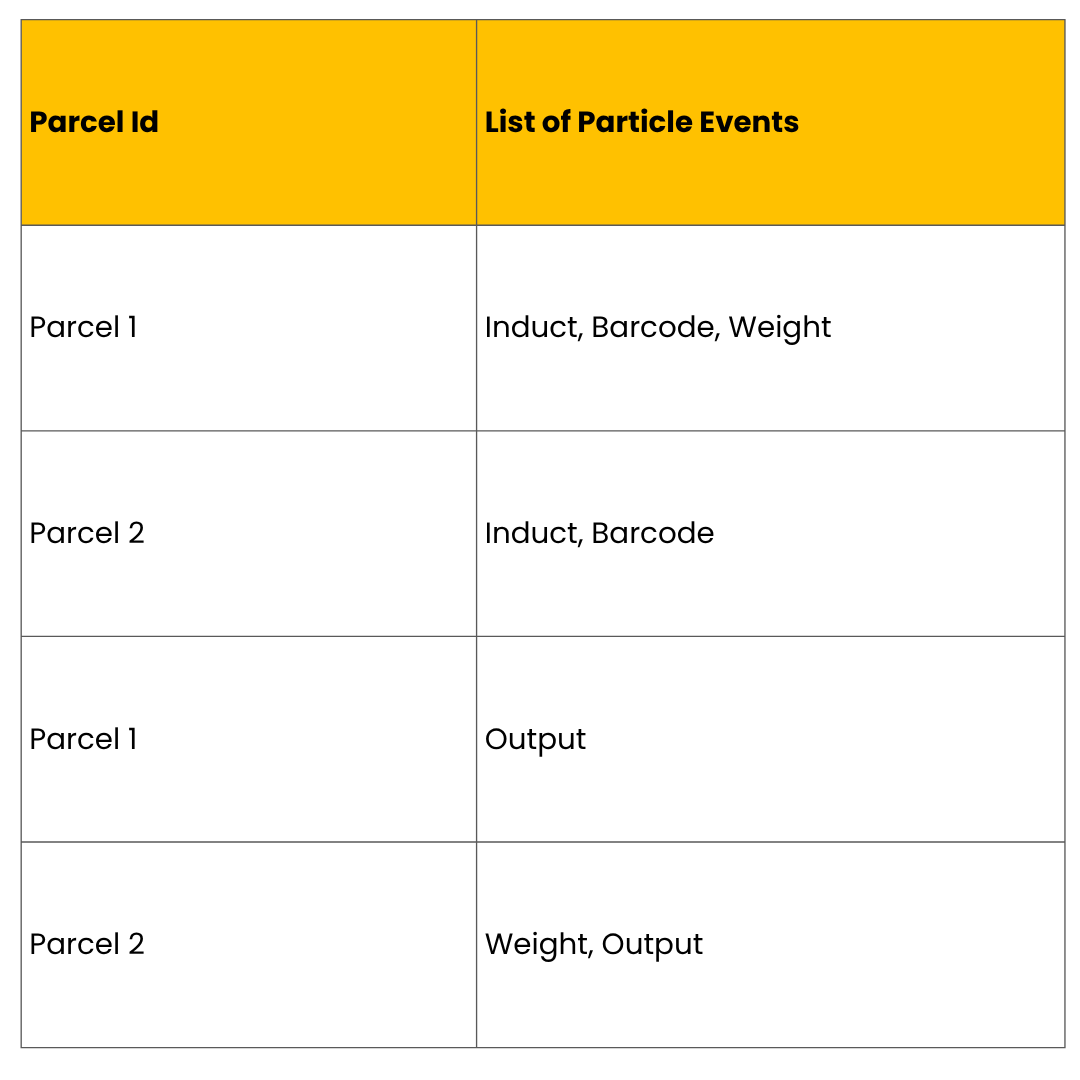
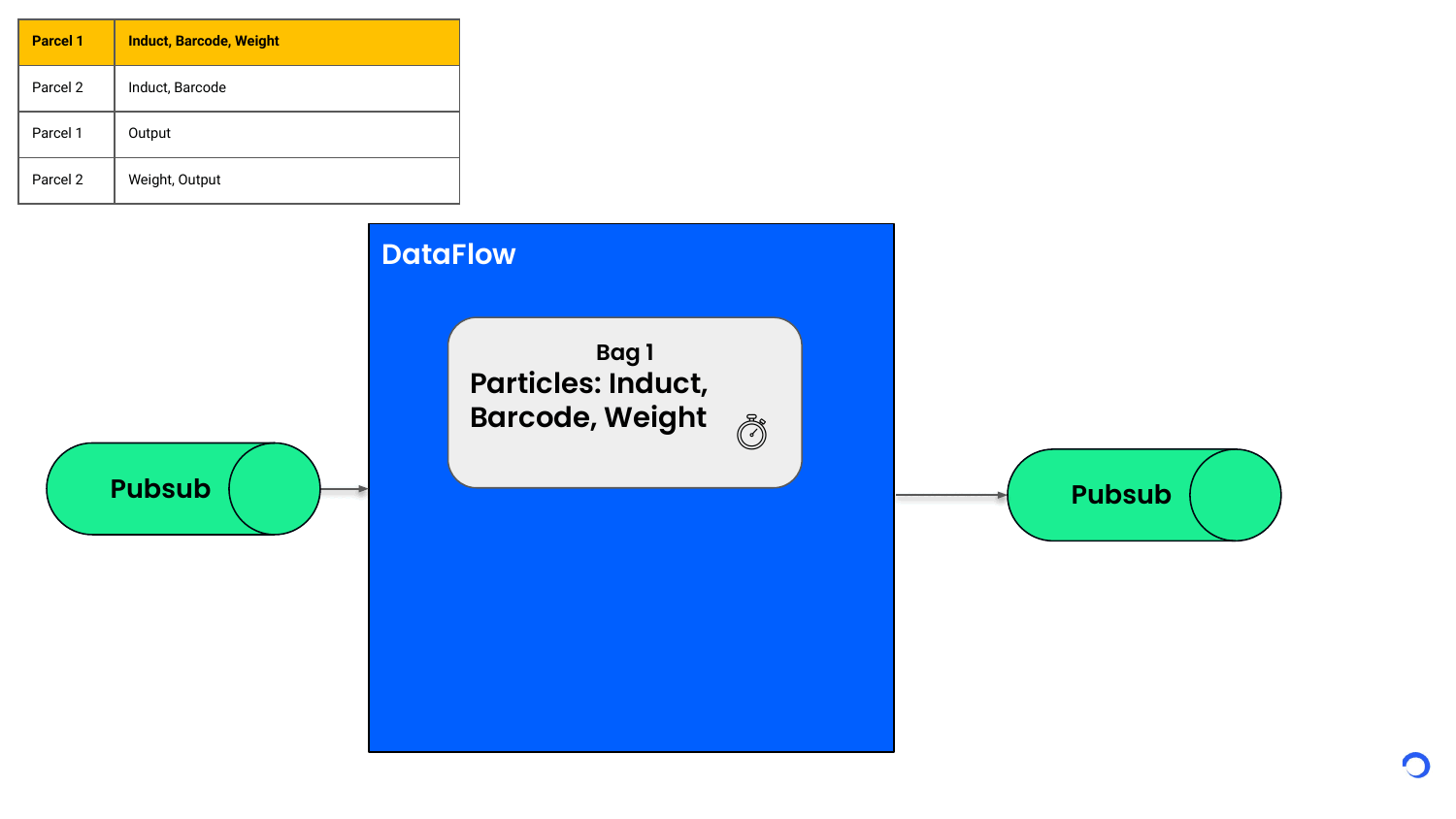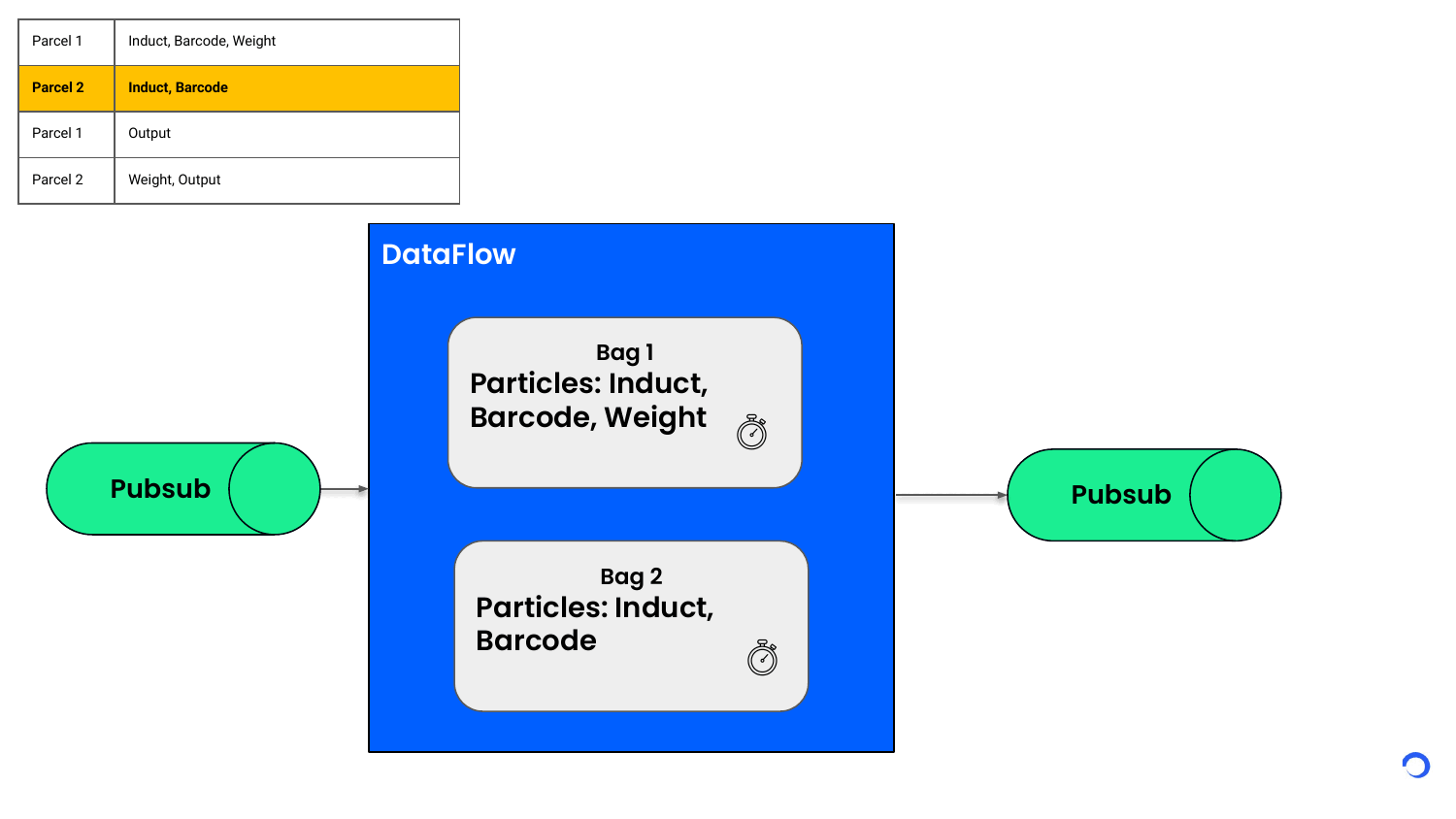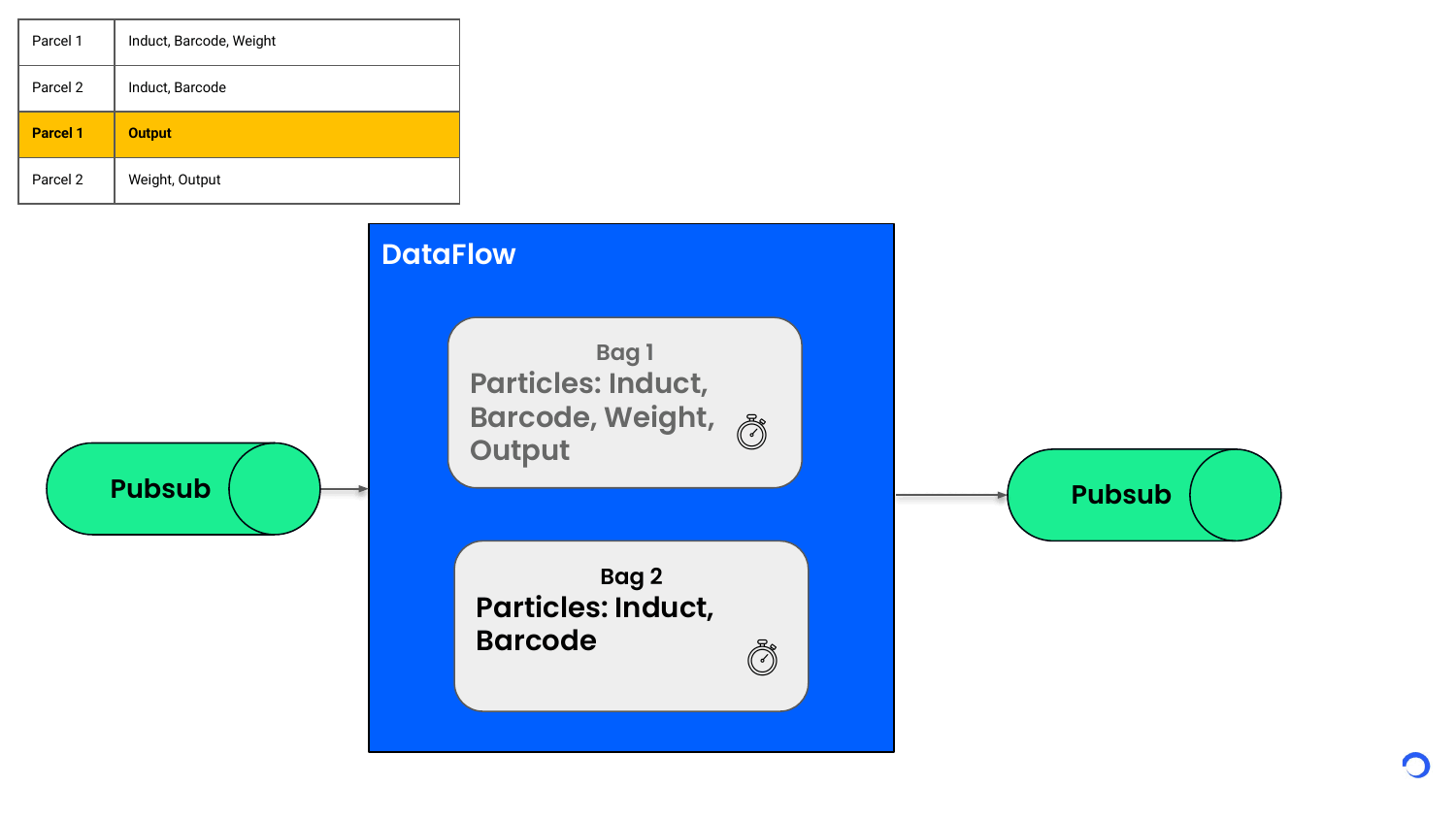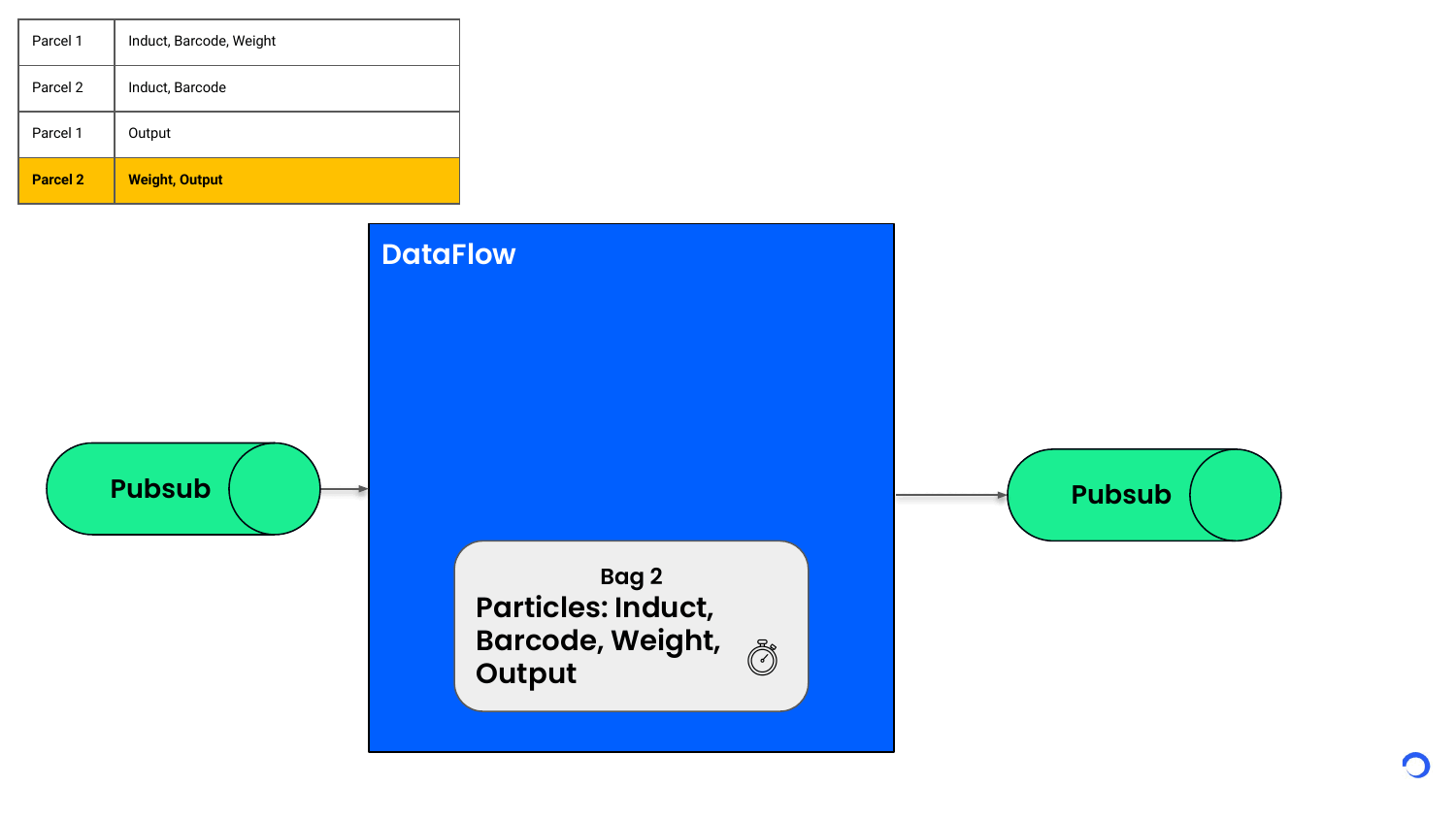
Based on the key (in this case, the Id of the parcel), Dataflow can group the events and partition them into separate buckets called Bags. This bag contains the state of a single parcel. All the freshly arriving events for that parcel will land into this bag state based on the key.
Whenever the Bag ends up having a complete list of particle events to create a sort event, the sort event is published to an external system and bag state is flushed. Whether a particle event arrives now or 5 minutes later, it’s held in the bag state and processed only when all the required particle events have arrived. In case all the required events don’t arrive in a set time, we can expire the bag state automatically.
In Apache Beam’s programming model, a complex job is broken into several small transformations and then linked to create a pipeline of transformations. Whenever data arrives in this pipeline it goes through these series of transformations to get processed.
An individual step in this pipeline is like a Function called Do Function(DoFn for short). As the name suggests it’s like an action where you can write code to do your transformation and return your result to the next stage. This DoFn is very powerful, it gives you a simple abstraction to write your logic and it can be further broken into small special lifecycle methods which can be called conditionally.
So the first DoFn in our pipeline creates a key which is parcel Id for each event. The second DoFn is a stateful Transformation. It not only processes the data but also creates a state called Bagstate per key id with a timer on it. This state is handled by Apache Beam workers
So far here is what we did
Dataflow automatically spins VM up or down based on the load. In our case, we processed 12k–15k events/sec using just 2–3 VMs. We tweaked the default CPU threshold for scaling from 80% to 65% to ensure smoother transitions.
The state moves with the workload. Even during code deployments or node failures, thanks to the magic of Google Dataflow, state is preserved and migrated as long as the DAG structure remains consistent. This makes rolling changes safe and predictable.
Dataflow comes with native GCP connectors which provides seamless, reliable integration. We didn’t need to manage connection logic like batching, pulling messages from the Pubsub topic or acknowledging.
Deployment changes that altered the DAG structure required careful handling. We had to safely move unprocessed data to a temporary store before switching versions to avoid data loss. This requires stopping the streaming pipeline and waiting until the state is cleared from memory. This is a necessary trade-off for long-term maintainability.
With Apache Beam, and Dataflow, we built a robust, real-time event consolidation pipeline; without reinventing the wheel. The right tools let us focus on business logic instead of plumbing, helping us deliver a scalable, resilient solution with minimal overhead.
References:
